前述
本篇先讲解MySQL索引的三种数据结构实现:B+Tree索引、Hash索引、Full-Text索引。然后讲解InnoDB 和MyISAM存储引擎B+Tree索引的差异。最后浅谈索引优化。
MySQL的索引是存储引擎层而不是服务器层实现的。所以,并没有统一的索引标准。
MySQL索引数据结构
1: B+Tree索引
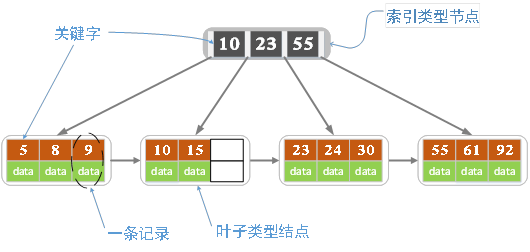
上图是一个简单的B+Tree结构,它有如下特点:
1)节点分内部节点和叶子节点。各叶子节点到根节点的高度一致。
2)内部节点不存储数据,只存储key,数据只存储在叶子节点上。
3)内部节点的key都是按从小到大的顺序排列的。对于一个给定的key,它的左子树的key都小于它,右子树的key都大于或等于它。
4)每个叶子节点都有一个指针指向下一个节点,方便顺序遍历和范围查询。
更多B+Tree结构的知识,参考文章B树和B+树的插入、删除图文详解
基于上述B+Tree的特点,B+Tree索引有如下优点:
1)内部节点不存储数据,可以容纳更多的索引项,可以定位更多的叶子节点,降低了树的高度,从而减少了索引查询的IO次数。通常数据库的索引B+Tree高度是2或者3。
2)由于叶子节点之间有指针,方便遍历和范围查询,而且结果排序。
2: Hash索引
Hash索引有以下特点:
1)快,对于一个确定的Key,查询时间复杂度为O(1)。
2)索引是离散的,因此不支持范围查询和排序。
3)由于需要完整的key计算Hash值,因此Hash索引不支持匹配查询,只支持 =,IN 等值查询。
4)数据量比较大时,产生冲突的概率变大,维护Hash索引的成本变高。
备注:Memory引擎默认索引即为Hash索引,InnoDB引擎提供自适应Hash索引。
3: Full-Text索引
对于一个给定的key,如果希望匹配过滤查询,可以使用LIKE模糊匹配。但是由于B+Tree索引最左匹配的原则,类似%key%的查询,B+Tree索引将失效,因此此时需要全文索引。
MyISAM 和 InnoDB 存储引擎均支持全文索引,只在文本类型如char,varchar,text上可以应用全文索引。
InnoDB B+Tree索引的分类
1: 主键索引
在创建表的时候通过PRIMARY KEY指定。如果创建表时未指定主键,会选择一个非空的唯一索引作为主键,如果没有这样的索引,MySQL会创建一个数字id作为主键。每个表只能有一个主键。
InnoDB的主键是一种聚簇索引,它的叶子节点存储了key和对应的数据。关于聚簇索引,后面关于InnoDB和MYISAM B+Tree索引机制的差异会详细谈及。
2: 唯一索引
唯一索引相对主键索引,允许为空,且每个表能存在多个唯一索引。
3: 普通索引
普通索引相对于主键索引,叶子节点存储的是key和对应的主键id值,因此如果未索引覆盖,可能产生回表查询。下面先解释下索引覆盖和回表。
1)回表
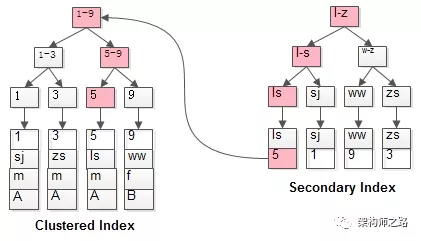
上图是下面user表的主键索引和普通索引name的回表现象。
如果需要查询的是SELECT id, name, sex FROM user WHERE name="zhangsan"。此时由于sex列并不在普通索引name的key里面,因此需要再通过主键查询拿到具体的数据。这种两次查询的现象就叫回表。
MySQL有自己的查询优化器,当检查到查询字段太多,比如SELECT * FROM table WHERE name=“zhangsan”,优化器会选择直接通过主键索引查询,从而避免产生回表。可以通过EXPLAIN指令查看某一条SQL语句走的是哪一个索引。
CREATE TABLE user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
2)索引覆盖
对于上面的查询,如果只查询id和name字段,那么普通索引name的key就能提供所需的字段,不需要再回表查询,这就是索引覆盖。为了查询sex时也能索引覆盖,我们可以建一个name和sex字段的多列索引。
参考资料:
InnoDB和MyISAM索引差异
下图是MyISAM引擎的索引图,图片来自网络,侵权请告知删除。
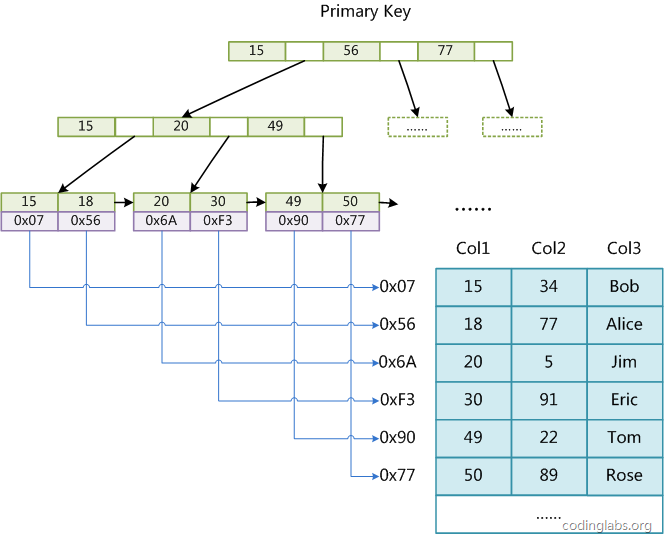
可以看到,MyISAM引擎的索引也是一种B+Tree数据结构,不过叶子节点存储的是key和行记录指针。这种叶子节点不储存行数据的索引称为非聚集索引,相对应的,InnoDB引擎的主键索引就是聚集索引,它的叶子节点存储key和行数据。
相对于InnoDB索引,当出现行移动或页分离时,数据移动更少。由于MyISAM的主键和普通索引都是相同的存储机制,因此对于普通索引,没有回表现象的产生。
说明:页是MySQL的存储单元,默认大小为16k。对于InnoDB,逻辑存储结构是一个表空间,表空间包含段,区,页。页里面才是具体的行记录数据。
索引优化
本节讲解一些索引优化技巧,相关内容来源于《高性能MySQL》。这里的索引仅仅指InnoDB存储引擎的B+Tree索引。
1)对于普通索引查询,尽可能使用索引覆盖,避免回表。
2)避免多个范围查询条件。
对于范围查询条件,MySQL无法再使用范围列后面的其它索引列了。我们可以把它改成多个等值条件查询,等值查询没有这个限制。如下面的age条件可以改成IN等值查询。
SELECT id, name, age
FROM ueser
WHERE created_date >= "2019-01-01"
and age BETWEEN 18 AND 25;
3)优化排序。索引可以用来排序,结合LIMIT限制提升性能。
4)由于最左匹配原则,对于多列索引,索引列的顺序很关键。因此,需要将选择性更高的列放在索引最前面。(为了避免随机IO和排序需要,可能这条就不适用了)
5)维护索引和表,整理数据碎片化(OPTIMIZE TABLE)。
非索引查询优化
1)避免查询不必要的记录。如返回所有的列,联表查询返回所有的列。
2)切分和分联关联查询。这条是为了上条避免查询不必要的记录。MySQL连接池作用,网络开销很小。避免磁盘IO应重于网络权重。
3)充分利用MySQL查询的优化器,关于优化器参考其他资料。
后述
参考资料:
《高性能MySQL》第五张和第六章